Abstract
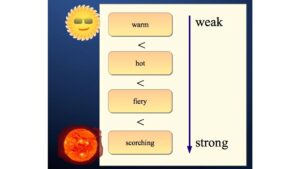
Adjectives like good, great, and excellent are similar in meaning, but differ in intensity. Intensity order information is very useful for language learners as well as in several NLP tasks, but is missing in most lexical resources (dictionaries, WordNet, and thesauri). In this paper, we present a primarily unsupervised approach that uses semantics from Web-scale data (e.g., phrases like good but not excellent) to rank words by assigning them positions on a continuous scale. We rely on Mixed Integer Linear Programming to jointly determine the ranks, such that individual decisions benefit from global information. When ranking English adjectives, our global algorithm achieves substantial improvements over previous work on both pairwise and rank correlation metrics (specifically, 70% pairwise accuracy as compared to only 56% by previous work). Moreover, our approach can incorporate external synonymy information (increasing its pairwise accuracy to 78%) and extends easily to new languages. We also make our code and data freely available.